Docs
Cluster-as-a-service - Kubernetes
Cluster-as-a-service - Kubernetes
This article describes how to deploy and use a Kubernetes cluster using JASMIN Cluster-as-a-Service (CaaS).
Introduction
Kubernetes is an open-source system for automating the deployment, scaling and management of containerised applications.
Kubernetes is an extremely powerful system, and a full discussion of its capabilities is beyond the scope of this article - please refer to the Kubernetes documentation. This article assumes some knowledge of Kubernetes terminology and focuses on things that are specific to the way Kubernetes is deployed by CaaS.
In CaaS, Kubernetes is deployed in a single-master configuration using Rancher Kubernetes Engine (RKE) . This configuration was chosen so that a single external IP can be used for SSH access to the cluster and for ingress - external IPs are a scarce resource in the JASMIN Cloud and the number available to each tenancy is limited. It is for this reason that load-balancer services are also not available. Highly-available (HA) configurations may be available in the future.
All externally-exposed services, including the Kubernetes API, are authenticated using the Identity Manager, meaning that FreeIPA groups can be used to control access to the cluster.
The following services are also configured by CaaS (described in more detail later):
- The Nginx Ingress Controller
- The Openstack Cloud Provider (Block Storage and Metadata only)
- Jetstack’s cert-manager
- The Kubernetes dashboard
Cluster configuration
The following variables are available when creating a Kubernetes cluster:
| Variable | Description | Required? | Can be updated? |
|---|---|---|---|
| Identity manager | The CaaS Identity Manager that is used to control access to the cluster. | Yes | No |
| Version | The Kubernetes version to use. The available versions are determined by the RKE version used by the CaaS configuration. This can be changed after initial deployment to upgrade a cluster to a newer Kubernetes version. Before doing this, you should back up your cluster - in particular, you should take a snapshot of the etcd database and make sure any data in persistent volumes is backed up. | Yes | Yes |
| Worker nodes | The number of worker nodes in the cluster. This can be scaled up or down after deployment. When scaling down, there is currently no effort made to drain the hosts in order to remove them gracefully: we rely on Kubernetes to reschedule terminated pods. This may change in the future. | Yes | Yes |
| Master size | The size to use for the master node. The master node is configured to be unschedulable, so no user workloads will run on it (just system workloads). | Yes | No |
| Worker size | The size to use for worker nodes. Consider the workloads that you want to run and pick the size accordingly. The capacity of the cluster can be increased by adding more workers, but the size of each worker cannot be changed after the first deployment. | Yes | No |
| Root volume size | The size of the root volume of cluster nodes, in GB. This volume must be sufficiently large to hold the operating system (~3GB), all the Docker images used by your containers (which can be multiple GBs in size) and all the logs and ephemeral storage for your containers. For reference, Google Kubernetes Engine (GKE) deploys hosts with 100GB root disks by default. At least 40GB is recommended. | Yes | No |
| External IP | The external IP that will be attached to the master node. This IP is where the Kubernetes API will be exposed, and can be used for SSH access to the nodes. | Yes | No |
| Admin IP ranges | One or more IP ranges from which admins will access the Kubernetes API and dashboard (if enabled), in CIDR notation . Any attempt to access the API or dashboard from an IP address that is not in these ranges will be blocked. Access to the Kubernetes API may allow the creation of resources in your cluster, so it is recommended that this range be as small as possible. If you are not sure what value to use here, contact your local network administrator to find out the appropriate value for your network. | Yes | Yes |
| Kubernetes dashboard | Indicates whether to deploy the Kubernetes dashboard. If selected, the Kubernetes dashboard will be available at the configured domain (see below). | Yes | Yes |
| Dashboard domain | The domain to use for the Kubernetes dashboard. If left empty, dashboard.<dashed-external-ip>.sslip.io is used. For example, if the selected external IP is 192.171.139.83, the domain will be dashboard.192-171-139-83.sslip.io. If given, the domain must already be configured to point to the selected External IP , otherwise configuration will fail. Only use this option if you have control over your own DNS entries - the CaaS system or Kubernetes will not create a DNS entry for you. |
No | No |
Accessing the cluster
Kubernetes is configured to use the OpenID Connect support of the Identity Manager for authentication and authorisation. This means that all interactions with the cluster are authenticated and authorised against the users in FreeIPA, via the Keycloak integration.
Using the dashboard
If the option to deploy the dashboard was selected, the Kubernetes dashboard
will be available at https://<dashboard domain>. Upon visiting the
dashboard, you will be redirected to Keycloak to sign in:
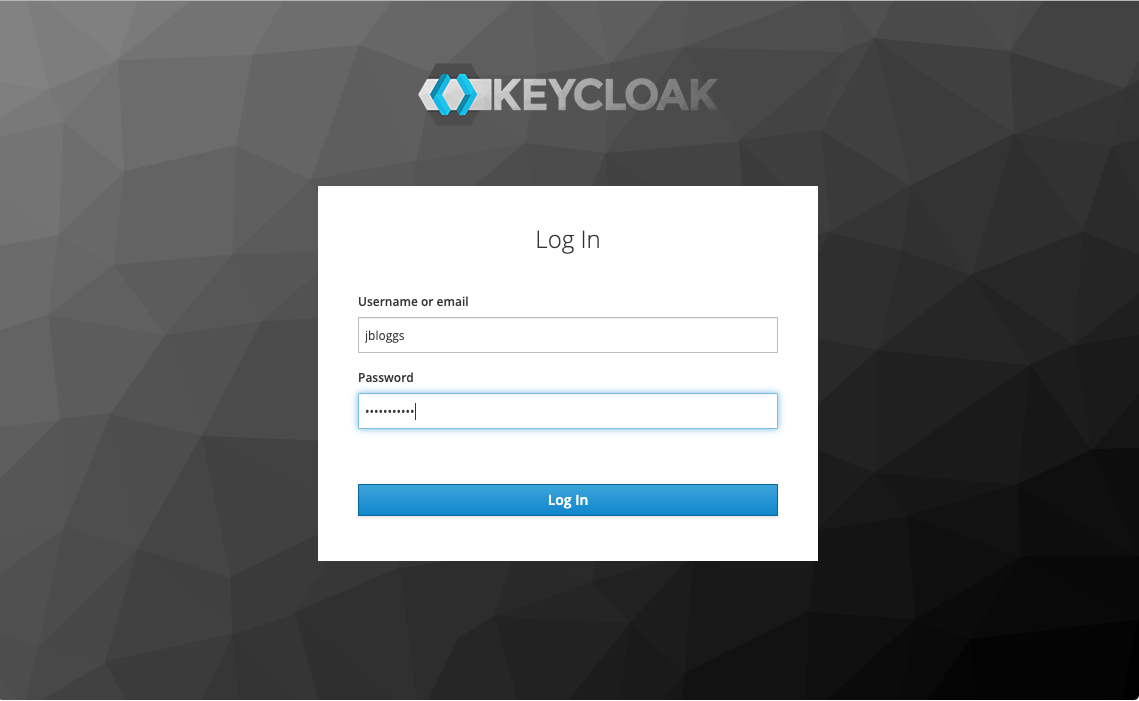
Any user that exists in your FreeIPA database is able to log in to the dashboard, but only those with permissions assigned for the cluster will be able to see or do anything. Here is an example of what a user with no permissions will see:
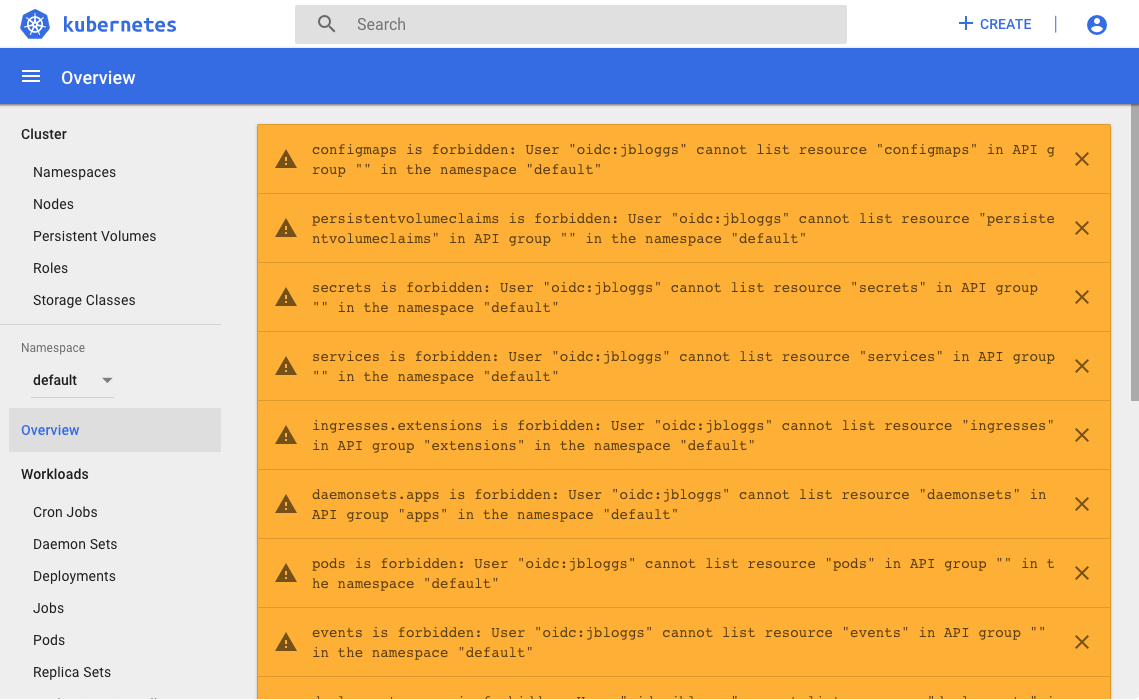
And here is an example of what a user with full admin rights will see (see Using Kubernetes RBAC below):
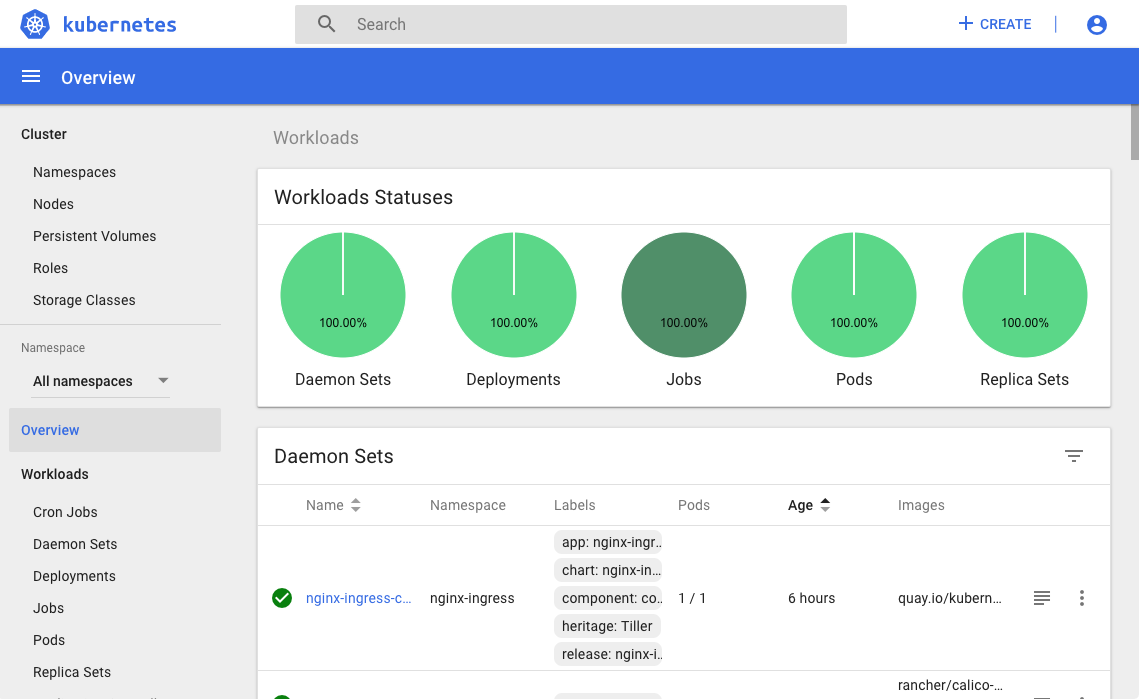
Using kubectl
This section assumes that you have kubectl , the Kubernetes command-line client, installed on your workstation. In order to authenticate with Keycloak, you must also install the kubelogin plugin, which provides OpenID Connect authentication for kubectl.
In order to configure OpenID Connect, you need to know the client ID and secret of the OpenID Connect client for your Kubernetes cluster in Keycloak. If you are an admin, you can find this information in the Keycloak admin console - the client will be named after the cluster. If you are not an admin, your admin should provide you with this information.
Use the following commands to configure kubectl to connect to your Kubernetes cluster using your Identity Manager, replacing the variables with the correct values for your clusters:
# Put the configuration in its own file
export KUBECONFIG=./kubeconfig
# Configure the cluster information
kubectl config set-cluster kubernetes \
--server https://${KUBERNETES_EXTERNAL_IP}:6443 \
--insecure-skip-tls-verify=true
Cluster "kubernetes" set.
# Configure the OpenID Connect authentication
kubectl config set-credentials oidc \
--auth-provider=oidc \
--auth-provider-arg=idp-issuer-url=https://${ID_GATEWAY_DOMAIN}/auth/realms/master \
--auth-provider-arg=client-id=${CLIENT_ID} \
--auth-provider-arg=client-secret=${CLIENT_SECRET}
User "oidc" set.
# Configure the context and set it to be the current context
kubectl config set-context oidc@kubernetes --cluster kubernetes --user oidc
Context "oidc@kubernetes" created.
kubectl config use-context oidc@kubernetes
Switched to context "oidc@kubernetes".Once kubectl is configured, use the oidc-login plugin to authenticate with Keycloak and obtain an ID token. Running this command launches a temporary lightweight web server on your workstation that performs the authentication flow with Keycloak. A browser window will open where you enter your username and password:
kubectl oidc-login
Open http://localhost:8000 for authentication
You got a valid token until 2019-07-11 21:58:06 +0100 BST
Updated ./kubeconfigYou can now use kubectl to query the Kubernetes resources to which you have been granted access:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kubernetes-master-0 Ready controlplane,etcd 12h v1.13.5
kubernetes-worker-0 Ready worker 12h v1.13.5
kubernetes-worker-1 Ready worker 12h v1.13.5
kubernetes-worker-2 Ready worker 12h v1.13.5Using Kubernetes RBAC
Kubernetes includes a powerful Role-Based Access Control (RBAC) system . A full discussion of the RBAC system is beyond the scope of this documentation, but this section gives some examples of how RBAC in Kubernetes can be used in combination with FreeIPA groups to allow fine-grained access to the cluster.
For every Kubernetes cluster that is deployed, CaaS automatically creates a
group in FreeIPA called <clustername>_users. This group, along with the
admins group, are assigned the cluster-admin role using a
ClusterRoleBinding, which grants super-user access to the entire cluster. In
order to grant a user super-user access to the cluster, they just need to be
added to one of these groups (depending on whether you want them to be a
super-user on other clusters as well).
It is also possible to create additional groups in FreeIPA and attach more restrictive permissions to them.
Example 1: Read-only cluster access
For example, suppose you have some auditors who require read-only access to
the entire cluster in order to know what workloads are running. The first
thing to do is
create a group in FreeIPA - in this case, you might create a group called
kubernetes_auditors. Once the group is created, you can reference it in
Kubernetes by using the prefix oidc: - in this case the group would be
referenced in Kubernetes as oidc:kubernetes_auditors. To grant read-only
access to this group for the entire cluster, create a ClusterRoleBinding
linking that group to the built-in view role:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-auditors-read
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: oidc:kubernetes_auditorsExample 2: Read-write namespace access
As another example, suppose you have some developers who want to deploy their
app in your cluster, and you want to grant them read-write access to a single
namespace to do this. Again, the first thing you would do is create a group in
FreeIPA called, for example, myapp_developers. You can then assign this
group the built-in edit role, but this time use a RoleBinding that is tied
to a particular namespace:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: myapp-developers-edit
namespace: myapp
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: edit
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: Group
name: oidc:myapp_developersUsing the cluster
It is beyond the scope of this documentation to discuss how to use Kubernetes: please refer to the Kubernetes documentation for that. This section describes some things about the way Kubernetes is deployed by CaaS that will make a difference to how your applications are deployed.
Ingress
In CaaS Kubernetes,
Ingress
resources
are handled by the
Nginx Ingress
Controller
, which is exposed at
the external IP used by the master node. The Ingress Controller supports a
wide range of Ingress annotations that can be used to customise the
behaviour for particular services - visit the documentation for more details.
In order to expose a service using an Ingress resource, each host given in
the resource specification must have a DNS entry that points to the external
IP of the master node (where the Ingress Controller is listening). CaaS or
Kubernetes will not create these DNS records for you, and it is not
possible to use an IP address as a host. If you cannot create or edit DNS
records, you can use
xip.io
(or similar services) - these
are “magic domains” that provide DNS resolution for any IP address using
domains of the form [subdomain.]<ip>.xip.io.
TLS with cert-manager
CaaS Kubernetes deployments also include
Jetstack’s cert-
manager
, which provides Kubernetes-
native resources for obtaining and renewing SSL certificates - visit the
documentation for more information. CaaS installs a ClusterIssuer called
letsencrypt that can automatically fetch and renew browser-trusted SSL
certificates from
Let’s Encrypt
using
ACME
.
By using annotations, certificates can be fetched automatically for Ingress
resources:
apiVersion: extensions/v1
kind: Ingress
metadata:
name: myapp
annotations:
kubernetes.io/ingress.class: "nginx"
cert-manager.io/cluster-issuer: "letsencrypt"
spec:
tls:
- hosts:
- example.example.com
secretName: myapp-tls # This secret will be created by cert-manager
rules:
- host: example.example.com
http:
paths:
- path: /
pathType: prefix
backend:
service
name: myapp
port:
number: 8080Storage
CaaS Kubernetes is also configured to take advantage of the fact that it is
running on
Openstack
. In particular, a
storage
class
is
installed that can dynamically provision
Cinder
volumes in response to
[persistent volume
claims](
https://kubernetes.io/docs/concepts/storage/persistent-
volumes/#persistentvolumeclaims) being created. This storage class is called
csi-cinder-sc-delete, and is consumed like this:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
storageClassName: csi-cinder-sc-delete
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10GiIf there is enough quota available, this persistent volume claim should result
in a new Cinder volume being provisioned and bound to the claim. The Cinder
volume will show up in the Volumes tab of the JASMIN Cloud Portal with a
name of the form kubernetes-dynamic-pvc-<uuid>.