Docs
Orchid GPU cluster
Details of JASMIN's GPU cluster, ORCHID
GPU cluster spec
The JASMIN GPU cluster is composed of 16 GPU nodes:
- 14 x standard GPU nodes with 4 GPU Nvidia A100 GPU cards each
- 2 x large GPU nodes with 8 Nvidia A100 GPU cards
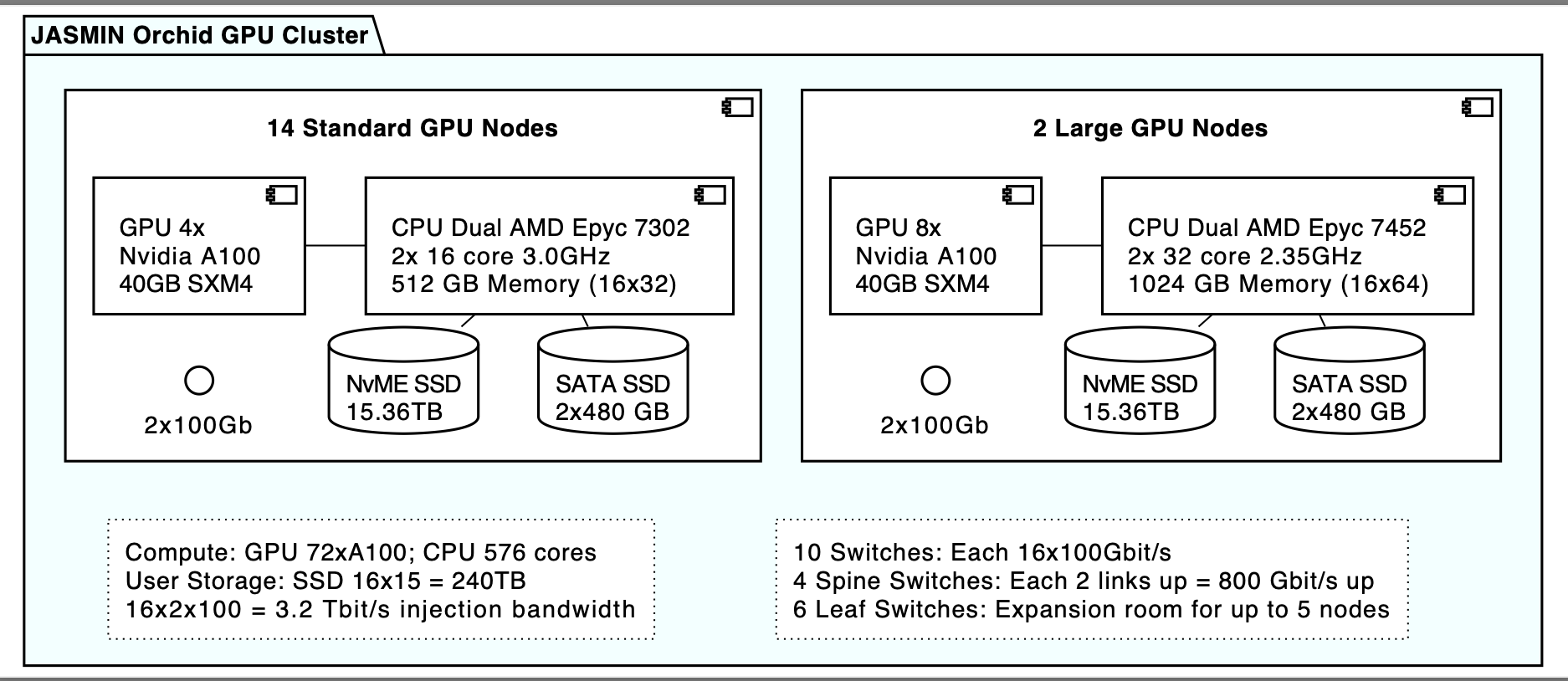
Notes:
gpuhost015andgpuhost016are the two largest nodes with 64 CPUs and 8 GPUs each.- the actual number of nodes may vary slightly over time due to operational reasons. You can check which nodes are available by checking the
STATEcolumn insinfo --partition=orchid.
Request access to ORCHID
Before using ORCHID on JASMIN, you will need:
- An existing JASMIN account and valid
jasmin-loginaccess role: Apply here - Subsequently once
jasmin-loginhas been approved and completed, theorchidaccess role: Apply here
The jasmin-login access role ensures that your account is set up with access to the LOTUS batch processing cluster, while the orchid role grants access to the ORCHID cluster and the GPU interactive node.
Note: In the supporting info on the orchid request form, please provide details
on the software and the workflow that you will use/run on ORCHID.
Submit a GPU batch job
Use the following Slurm command to submit a GPU batch job:
sbatch --gres=gpu:1 --partition=orchid --account=orchid --qos=orchid gpujobscript.sbatchor add the following preamble in the job script file:
#SBATCH --partition=orchid
#SBATCH --account=orchid
#SBATCH --qos=orchid
#SBATCH --gres=gpu:1Multi-instance GPU partition
This feature is new as of Spring 2026.
A new partition with the multi-instance GPU (MIG) feature has been added to the ORCHID cluster. This partition is dedicated for small workflows or machine learning processes that don’t use the whole graphics card or parallel processing across GPU nodes. The benefit of using this partition is shorter scheduling time for smaller jobs.
To access this partition, specify the following directives in your job script:
#SBATCH --partition=gpumig
#SBATCH --account=orchid
#SBATCH --qos=gpumig
#SBATCH --gres=gpu:1g.10gb:1Partition and QoS limits
Below is the table of Quality of Services (QoS) available on ORCHID and their limits.
If, for example, the CPU limit is exceeded, then the job is expected to be in a pending state with the reason
QOSGrpCpuLimit.
| Partition | QoS | Priority | Max wall time | Max jobs per user |
|---|---|---|---|---|
orchid |
orchid |
350 | 24 hours | 8 |
orchid |
orchid48* |
350 | 48 hours | 8 |
gpumig |
gpumig |
700 | 12 hours | 4 |
* We provide this QoS (orchid48) as an on-request basis. If your workflow needs to run on a GPU for 2 days, please
contact the JASMIN helpdesk and justify the resource request. Access to this QoS is time-bound (maximum two months).
GPU interactive node outside Slurm
There is an interactive GPU node gpuhost001.jc.rl.ac.uk, not managed by Slurm, which has the same spec as
other ORCHID nodes. You can access it directly from the JASMIN login servers for prototyping and
testing code prior to running as a batch job on ORCHID:
Make sure that your initial SSH connection to the login server used the -A (agent forwarding) option, then:
ssh gpuhost001.jc.rl.ac.uk# now on gpu interactive node
nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.20 Driver Version: 570.133.20 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA A100-SXM4-40GB On | 00000000:01:00.0 Off | 0 |
| ... | ... | ... |Software Installed on the GPU cluster
- CUDA version 13 (other versions will be available soon via the module environment)
- If you want to use CUDA Version 12.8, please add the following to your path:
export PATH=/usr/local/cuda-12.8/bin${PATH:+:${PATH}}
- If you want to use CUDA Version 12.8, please add the following to your path:
- CUDA DNN (Deep Neural Network Library) version 13
- cuda-toolkit - version 13.1
- Singularity-CE version 4.3.7-1.el9 - supports NVIDIA/GPU containers
- podman version 5.6.0
Please note that the cluster may have newer software available. For example, you can check the current CUDA version by running nvcc --version (nvidia-smi also shows the CUDA version, see example above). You can also check the Singularity version with singularity --version.